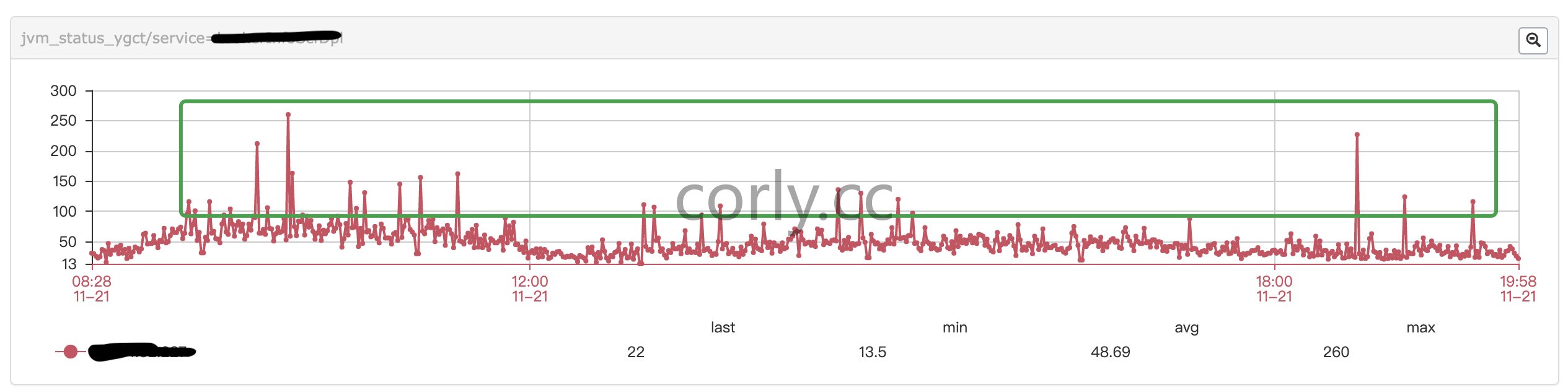
年轻代GC回收时间不稳定,会出现突刺
下图是每分钟yong gc 所消耗的时间,没有规律的突刺。
年轻代gc 使用的是 ParNew 并发收集,
数据流重导向可以将 standard output (简称 stdout) 与 standard error output (简称 stderr) 分别传送到其他的文件或装置去,而分别传送所用的特殊字符则如下所示:
- 标准输入 (stdin) :代码为 0 ,使用 < 或 << ;
- 标准输出 (stdout):代码为 1 ,使用 > 或 >> ;
- 标准错误输出(stderr):代码为 2 ,使用 2> 或 2>> ;
1 | INSERT INTO db1_name (field1,field2) SELECT field1,field2 FROM db2_name |
修改编码
1 | ALTER TABLE `article` |
导出整个数据库
1 | mysqldump -u [uname] -p[pass] db_name > db_backup.sql |
导出所有的数据库
1 | mysqldump -u [uname] -p[pass] --all-databases > all_db_backup.sql |
指定数据库中的表
1 | mysqldump -u [uname] -p[pass] db_name table1 table2 > table_backup.sql |
gzip 压缩
1 | mysqldump -u [uname] -p[pass] db_name | gzip > db_backup.sql.gz |
其他
1 | mysqldump -P 3306 -h [ip_address] -u [uname] -p[pass] db_name > db_backup.sql |
1 | mysql -u username -p -h localhost DATA-BASE-NAME < data.sql |
import large csv file
修改MySQL的配置文件,my.cnf
[mysqld]
max_allowed_packet=1000M
执行如下命令导入csv文件
1 | mysql -uroot -proot --local-infile shu_student -e " |
###自动备份数据库
1 | # /bin/bash |
1 | SELECT DISTINCT CONCAT('User: ''',user,'''@''',host,''';') AS query FROM mysql.user; |
1 | CREATE USER 'username'@'host' IDENTIFIED BY 'password'; |
1 | CREATE USER 'web'@'localhost' IDENTIFIED BY '123456'; |
1 | GRANT privileges ON databasename.tablename TO 'username'@'host'; |
1 | GRANT SELECT, INSERT ON test.user TO 'web'@'%'; |
用以上命令授权的用户不能给其它用户授权,如果想让该用户可以授权,用以下命令:
1 | SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword'); |
如果是当前登陆用户用
1 | SET PASSWORD = PASSWORD("newpassword"); |
1 | DROP USER 'username'@'host'; |
1 | SELECT table_schema "DB Name", |
从https://lucene.apache.org 下载Solr包。
我这里下载的版本是5.5的,官方给的启动方式:
/solr-5.3.1:$ bin/solr start -e cloud -noprompt
这里 -e cloud 是官方给的示例,如果不想用官方的示例,自己创建可以用如下方式
solr-5.5.0 bin/solr start -noprompt
//然后自己创建一个collection
solr-5.5.0 bin/solr create -c recruiting
新建的collection的存放位置:solr-5.5.0/server/solr/recruiting/
这里使用 mmseg4j 分词,下载地址:https://github.com/chenlb/mmseg4j-solr
将下载的jar包,移动到WEB-INF/lib下
solr-5.5.0 mv ~/Downloads/mmseg4j-* ./server/solr-webapp/webapp/WEB-INF/lib
修改新建的collection下的conf下的schema.xml文件,这时你发现并没有这个配置文件,但是你会发现有个managed-schema文件,打开一看里面有如下内容:This is the Solr schema file. This file should be named “schema.xml” and should be in the conf directory under the solr home(i.e. ./solr/conf/schema.xml by default)
所以将managed-schema文件重命名为schema.xml,修改配置文件,添加中文分词。
solr-5.5.0 vim server/solr/recruiting/conf/schema.xml
添加如下配置:
1 | <fieldType name="mmseg4j_complex" class="solr.TextField" positionIncrementGap="100"> |
上面添加了三个filedType,他们组要的区别为:
成功运行后如下:
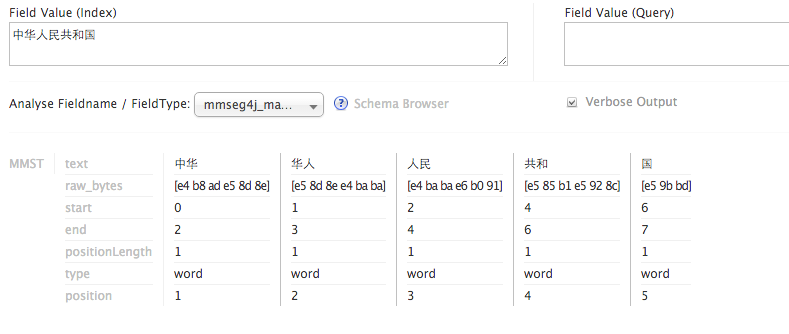
在schema.xml中添加field,默认有一个id字段,然后再添加你数据库中的字段。
1 | <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> |
题外话
copyField节点
如果我们的搜索需要搜索多个字段该怎么办呢?这时候,我们就可以使用copyField。
2
3
4
5
6
7
<copyField source="address" dest="all" />
<copyField source="description" dest="all" />
<copyField source="city" dest="all" />
<copyField source="district_name" dest="all" />
<copyField source="merchantCategory_name" dest="all" />
<copyField source="bank_name" dest="all" />我们将所有的中文分词字段全部拷贝至all中,当我们进行全文检索是,只用搜索all字段就OK了。
注意,这里的目标字段必须支持多值,最好不要存储,因为他只是做搜索。indexed为true,stored为false。
修改solrconfig.xml文件,位置solr-5.5.0/server/solr/recruiting/conf/solrconfig.xml。 添加如下配置
1 | <requestHandler name="/dataimport" |
在solr-5.5.0/server/solr/recruiting/conf/ 下创建data-config.xml 文件,配置如下:
1 | <dataConfig> |
将solr-dataimporthandler和mysql-connector两个jar包拷贝到solr-5.5.0/server/solr-webapp/webapp/WEB-INF/lib当中。
solr-5.5.0 cp dist/solr-dataimporthandler-5.5.0.jar server/solr-webapp/webapp/WEB-INF/lib
solr-5.5.0 mv ~/Downloads/mysql-connector-java-5.1.38.jar ./server/solr-webapp/webapp/WEB-INF/lib
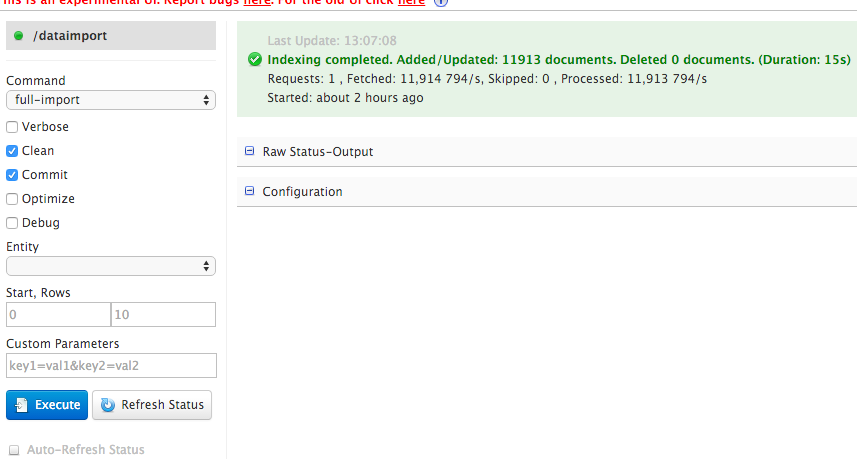
重启服务bin/solr restart,选择当前core为recruiting,然后点击dataimport,如果配置正确,就会出现如下图,点击Execute就可以了
通过**&**可以直接将命令丢到背景中运行,比如我们要将 /etc/ 整个备份成为 /tmp/etc.tar.gz 且不想要等待,那么可以这样做:
tar -zpcf /tmp/etc.tar.gz /etc &
在背景当中运行的命令,如果有 stdout 及 stderr 时,他的数据依旧是输出到萤幕上面的。所以,最佳的状况就是利用数据流重导向, 将输出数据传送至某个文件中。
tar -zpcvf /tmp/etc.tar.gz /etc > /tmp/log.txt 2>&1 &
观察目前的背景工作状态。
jobs [-lrs]
选项与参数:
-l :除了列出 job number 与命令串之外,同时列出 PID 的号码;
-r :仅列出正在背景 run 的工作;
-s :仅列出正在背景当中暂停 (stop) 的工作。
将背景工作拿到前景来处理
fg %jobnumber
让工作在背景下的状态变成运行中
➜ ~ jobs; bg %1; jobs
[1] + suspended sh fq.sh
[1] + 10348 continued sh fq.sh
[1] + running sh fq.sh
管理背景当中的工作
kill -9 %2
-9 :立刻强制删除一个工作;
nohup 可以让你在离线或注销系统后,还能够让工作继续进行。
nohup [命令与参数] <==在终端机前景中工作
nohup [命令与参数] & <==在终端机背景中工作
如果你再次登陆的话,可以使用 pstree 去查阅你的程序。
我们已经知道,如果事先在命令前加上 nohup 就可以在你关闭终端后继续运行程序。但是如果我们未加任何处理就已经提交了命令,该如何补救呢。
disown 它可以将指定任务从”后台任务”列表(jobs命令的返回结果)之中移除。一个”后台任务”只要不在这个列表之中,session 就肯定不会向它发出SIGHUP信号。
1 | # 移出最近一个正在执行的后台任务 |
问题描述
基因序列由字母G、A、T和C构成的字符串,现要判定一个基因中是否有结构的基因元素。
输入
输入有多组测试数据。每组有2行,第1行是由字母G、A、T和C构成的字符串str表示一个基因序列,第2行是一个由字母G、A、T和C构成的字符串str1表示的基因元素。
输出
对每组数据,统计str1在str中出现的次数。
输入样例
AGTCGATCGAGAGTTC
AG
TTTACCGAGA
TAC
输出样例
3
1
1 | public class Main1 { |
问题描述
给定线段PQ和三角形ABC,求三角形面积并确定线段PQ是否与三角形相交。
输入
有多组测试数据。输入的第一行上有正整数n,表示有n组测试数据。每组测试数据有2行:第一行上有6个整数x1 y1 x2 y2 x3 y3,整数之间用一个空格隔开,他们分别表示三角形ABC的三个顶点坐标A(x1,y1)、B(x2,y2)、C(x3,y3);第二行是4个整数u v w t,整数之间用一个空格隔开,他们表示线段PQ端点P和Q的坐标P(u,v),Q(w,t)。
输出
对输入中的每组测试数据,先输出一行,内容是“Case i:”,其中i是数组的编号(从1开始)。在下一行上输出三角形的面积(四舍五入保留1位小数),空一格后输出三角形与线段的相交情况:对给定的三角形ABC和线段PQ,如果线段PQ与三角形的边相交,那么输出“Yes”,否则输出“No”。约定:当线段PQ在三角形内部时,PQ与三角形的边不相交。
输入举例
2
0 0 4 4 0 4
1 2 1 3
0 0 3 4 0 4
0 -3 -1 -4
输出样例
Case 1:
8.0 No
Case 2:
6.0 No
1 | public class Main { |
1 | /** |